
Search at Intercom: Building our Elasticsearch cloud on AWS

Main illustration: Josh Daniel
In Intercom, we believe that shipping is our company’s heartbeat. Our product engineers are empowered to build great features, fast.
A large part of making this belief a reality is the idea of running less software. Every product team is burdened by the effort required to evolve and maintain complex infrastructure that powers their features. For this reason, we chose to run exclusively on AWS and wherever possible, we make use of battle-tested AWS services, be it RDS Aurora for our relational databases, the Simple Queue Service (SQS) for our async workers or ElastiCache for our caching layer.
However, as with any rule, there comes an exception, a case that cannot fit neatly into the principles we’ve outlined as a company. So how do we handle these exceptions? In Intercom, we were forced to answer these questions as we built out our search functionalities and embraced Elasticsearch.
This post is a version of a talk I gave at Elastic Community Conference recently. You can watch a video of that talk below, or read on to learn how we built our Elasticsearch cloud on AWS.
Core part of Intercom
Search is an indispensable part of Intercom. It underpins a whole host of core Intercom features – Inbox Views, API, Articles, the user list, Reporting, Resolution Bot, and our internal logging systems. Our search clusters contain more than 200TB of customer data, store more than 100 billion documents and, on at the peak on an average day, serve more than 13 million queries every minute. It does not just power the free text search functionality either – our Reporting pipeline is based on rich data aggregations running on Elasticsearch and our User, Message and Conversation matching features allow customers to perform complex predicate-based lookups against hundreds of data attributes and millions of documents using our search layer.
“Our search clusters contain more than 200TB of customer data, store more than 100 billion documents and can serve more than 13 million queries every minute”
At the time when we were building many of these features, there simply didn’t exist external Elasticsearch services that could give us the necessary dials to control this layer at scale, quality, and performance that we needed. So we decided to do something contrary to our engineering principles – run our search infrastructure ourselves on Elastic Compute Cloud hosts, or EC2 as it’s known. Doing this meant we also took on the responsibility of ensuring the product teams who use it and the infrastructure teams who maintain it have a great experience with a minimum of effort. This might be an exception to our “run less software” philosophy, but we were determined that it should never feel like it. We wanted it to feel seamless and invisible.
Three areas of focus
When we started the work of transparently automating away the biggest sources of frustration caused by managing search infrastructure, we decided to focus on three most expensive areas: applying security patches, performing software upgrades, and replacing failed EC2 instances.
All three, and security patching especially, occur frequently and so are very time expensive to perform for a product team. Stateless, ephemeral infrastructure like a set of web services running on EC2 can be rebuilt or upgraded relatively quickly by recycling the hosts, but stateful infrastructure like Elasticsearch is a different beast.
“How do you take a data- and infrastructure-heavy service like Elasticsearch and build automation around it that makes all that heavy maintenance as invisible as possible?”
Taking down data-heavy instances takes a long time as data might need to be relocated for clusters to remain available. This can cause surges in network traffic, destabilize the cluster and open the door to random failures in the relatively long window during which the operation is being performed.
So, how do you take a data- and infrastructure-heavy service like Elasticsearch and build automation around it that makes all that heavy maintenance as invisible as possible?
To start with, you need a mechanism to safely take a node out of the cluster without compromising the availability of data. Depending on the need, Elasticsearch provides two suitable mechanisms that can be used for this purpose:
If a node needs to be taken out of the cluster for brief maintenance (say replacing the version of the Linux kernel with a new one), Elasticsearch can use the rolling restart mechanism and mark the data as temporarily “unassigned.” No data movement takes place if the maintenance can be performed in a short enough time. This is achieved by setting the cluster.routing.allocation.enable setting to false for the duration of the work:
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": “none”
}
}
If a node needs to be completely removed from the cluster (due to hardware issues, for example), we can tell Elasticsearch to safely exclude the node and reallocate the data elsewhere while keeping the cluster fully available. Copied data is marked as “authoritative” only when the operation finishes:
PUT _cluster/settings
{
"transient" : {
"cluster.routing.allocation.exclude._ip" : "<node-ip>"
}
}
Now, the second part of the story is, once you know about these mechanisms, how can you write automation that safely scales them up to a dozen or so clusters running hundreds of nodes between them?
First, you need to provide some prerequisites and formal state checks for every operation to make your automation safe:
- Make sure the cluster is healthy and serving traffic both before and after each node is processed. Operations should not proceed further if the cluster is destabilized at any one time.
- Make sure that nodes are transparently removed from any load balancers and customer traffic safely drained away to other nodes to avoid customer impact and safely put back into rotation once the operation is complete.
Providing invisible management
To provide the needed level of this “invisible” management, we utilized a combination of two technologies – Chef and AWS Systems Manager (SSM). Chef is a widely used configuration management framework with plenty of community support and was a good engineering fit as it allows you to write lifecycle automation in a dialect of Ruby, one of the core languages Intercom is based on. We decided to use it to power the node-level automated lifecycle of EC2 instances as they join and leave the cluster, including things like Java and Elasticsearch installation, automatic provisioning and tuning of ephemeral SSDs that host the Elasticsearch data and more.
While Chef was good for managing the state of individual nodes, we needed a better tool for managing the co-ordinated cluster-wide workflows described above. SSM is an infrastructure control service that AWS themselves use for managing their vast EC2 resources via custom-made scripts called “commands”, and so came with good guarantees on scale and robustness. It provided some important advantages on top of Chef:
- Cron-like automated maintenance windows can be specified to run our workflow, so we can have automation running during off-peak hours.
- Flexible instance discovery using tags allows targeting only specific groups of instances. For example, we split the ES primary and replica data (called “shards”) per availability zone (AZ) to minimize the blast radius and let the system perform updates per AZ, always leaving the cluster in a healthy state.
- We implemented complex automation as Ruby tools and easily tied them into SSM commands, but also more importantly into GitHub and our CI/CD system allowing us to treat automation at the same level of operational excellence as we do our production codebase. This allows the actual code of the SSM command to be a thin wrapper that pulls the repository master, deploys, and executes the necessary command.
SSM executes the commands using an on-instance daemon agent called AWS SSM Agent. This architecture has both an advantage (it makes it very robust) and a downside in that there is no “outside” place that is executing your automation and thus you cannot target nodes that are experiencing failures or are turned off. For this purpose we extended the system to enqueue such operations (for example, deleting a failed or a stopped node from the cluster) to a simple external AWS Lambda function driven via a dedicated SQS queue.
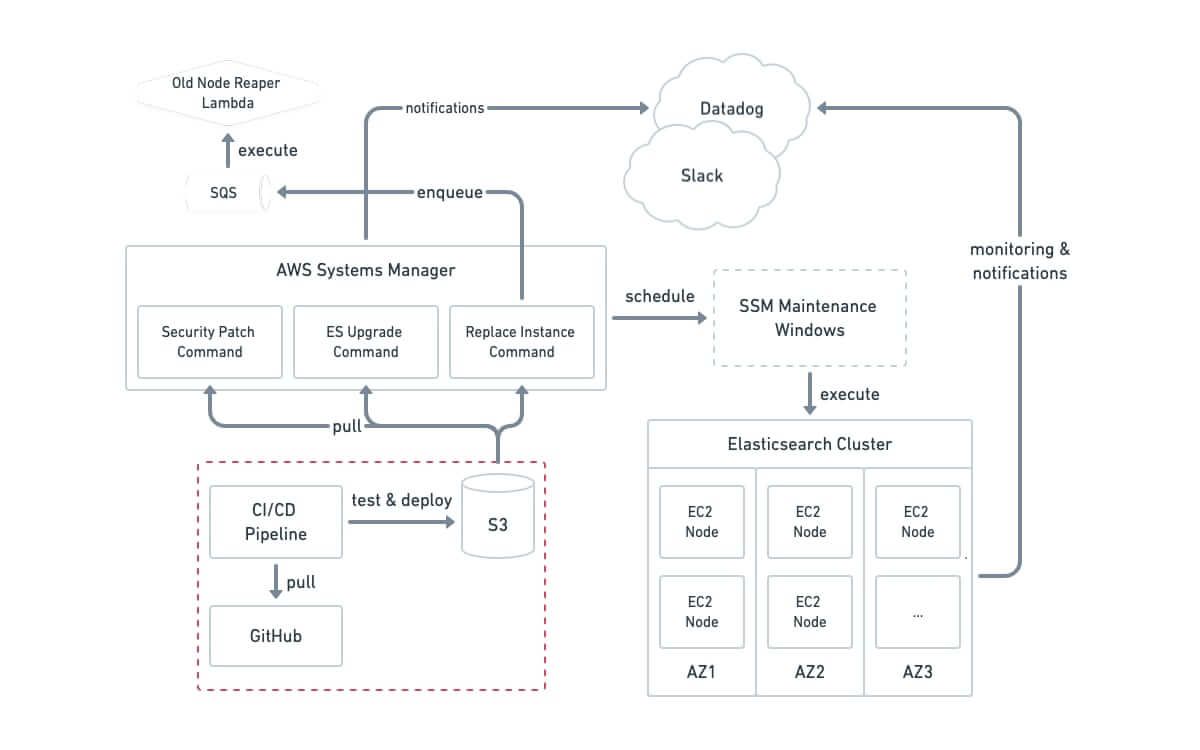
Architecture of the system
The system is integrated with Datadog, which our product teams use for monitoring, allowing tracking key metrics via easy-to-use dashboards, and Slack, which we use for intra-company communication, to proactively inform teams on actions being executed, ensuring high levels of operational visibility.
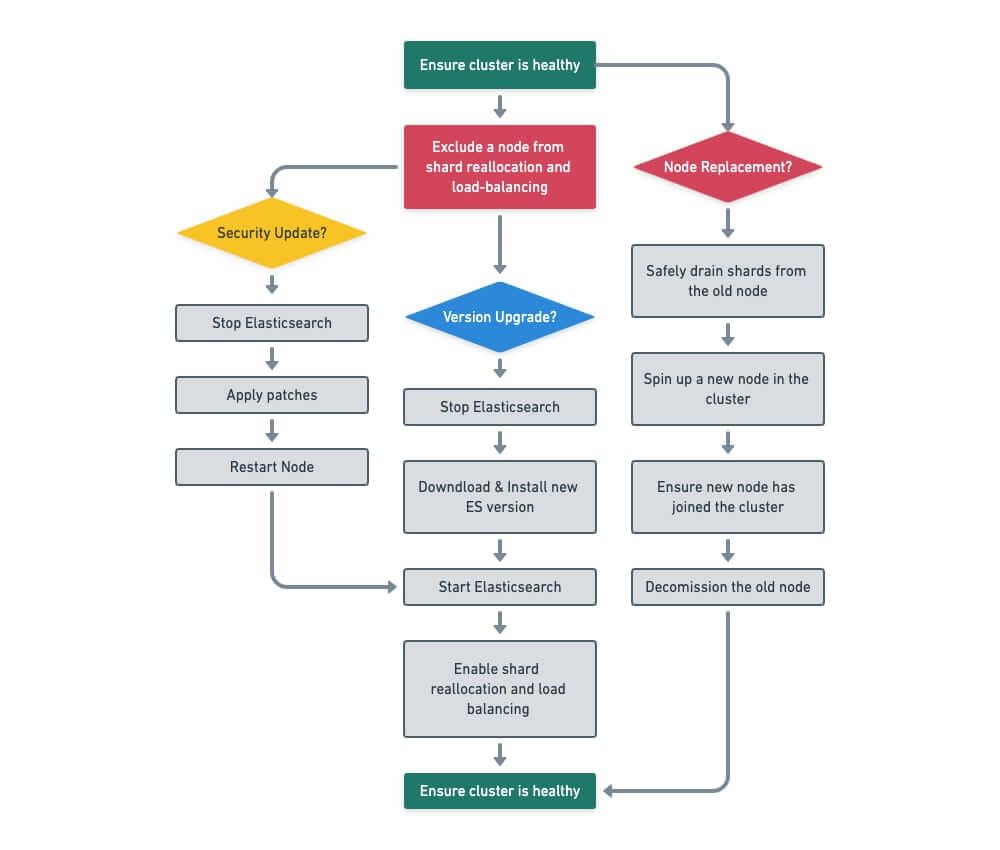
Key automation workflows
Saving time, money, and effort
This system allowed us to achieve massive time savings in performing infrastructure maintenance. For instance, when the ZombieLoad vulnerability hit the IT world in 2019, we just shrugged off the cost of the rollout – automation simply applied the fix across hundreds of Elasticsearch nodes as part of kernel security updates with no engineer involvement necessary.
“By thoughtfully accepting the cost of this exception and by conscientiously iterating on it, we were able to bring our Elasticsearch service back in line with our principles”
Keeping up with Elasticsearch versions to make sure Intercom can tap into the latest and greatest search features would previously require costly maintenance operations. Not any more – at the push of a button, we can upgrade the cluster version with zero downtime. We currently run all of our clusters on ES 7.9, just a few minor versions shy of the latest.
Finally, the ability to do a live change of node EC2 types provided significant cost savings and ensured we can easily right-size any of our search clusters to achieve the best price/performance ratio.
It wasn’t easy, but by thoughtfully accepting the cost of this exception and by conscientiously iterating on it, we were able to bring our Elasticsearch service back in line with our principles. This has allowed us greater flexibility without sacrificing the kind of product we like to build.







