
Building Resolution Bot: How to apply machine learning in product development

Main illustration: Kasia Bojanowska
We are at the start of a revolution in customer communication, powered by machine learning and artificial intelligence.
At Intercom, we have taken advantage of these technologies relatively early. Our Custom Bots and Resolution Bot already work for thousands of businesses every day. These bots help businesses deliver both radical efficiencies and better, faster support experiences.
So, modern machine learning opens up vast possibilities – but how do you harness this technology to make an actual customer-facing product?
Late last year, I spoke at the Predict Conference on how we built Resolution Bot, our intelligent support chatbot that can instantly resolve common questions. This post is based on that talk, and details our journey from early experimentation to release, as well as some valuable lessons we learned about how to implement machine learning (ML) in a real-world product.
The cupcake approach to building bots
Reading papers about how Google or IBM build their ML products, it’s easy to think only the very largest companies can afford to productize machine learning. Those companies need to spend a lot of time considering problems that will occur when a system has millions of users, and have to think carefully about ML tech debt given their scale. However, for smaller companies interested in delivering successful ML products, a lean approach can bring a lot of rewards.
At Intercom, we generally follow the cupcake approach to building product – start with the smallest functioning version and iterate fast from there.
“A complex system that works is invariably found to have evolved from a simple system that worked”
When it comes to machine learning, Gall’s Law applies: “A complex system that works is invariably found to have evolved from a simple system that worked.” ML products also require us to manage relatively large technology risks – this is an area where, unlike in most other product development, technical limitations might render the entire design impossible. We can’t assume the ML will always perfectly do what we want.
New software engineers quickly learn that a lot of complexity arises from error handling. Similarly, much of the complexity of ML products involves handling what happens when they make a mistake and in designing around imperfect performance. We can’t just build for the good path.
It’s also easy to over- or under- invest in the technology. It’s hard to balance investment optimally across ML, product, engineering, and design.
To address these challenges, as well as building “cupcakes,” we like to use a metaphor from computer science: ML products should be built “breadth-first”.
Don’t build three generations of ML tech before designing the first shippable design. Similarly, don’t design far beyond what the machine learning can deliver – instead, traverse the product development tree, one level of depth at a time.
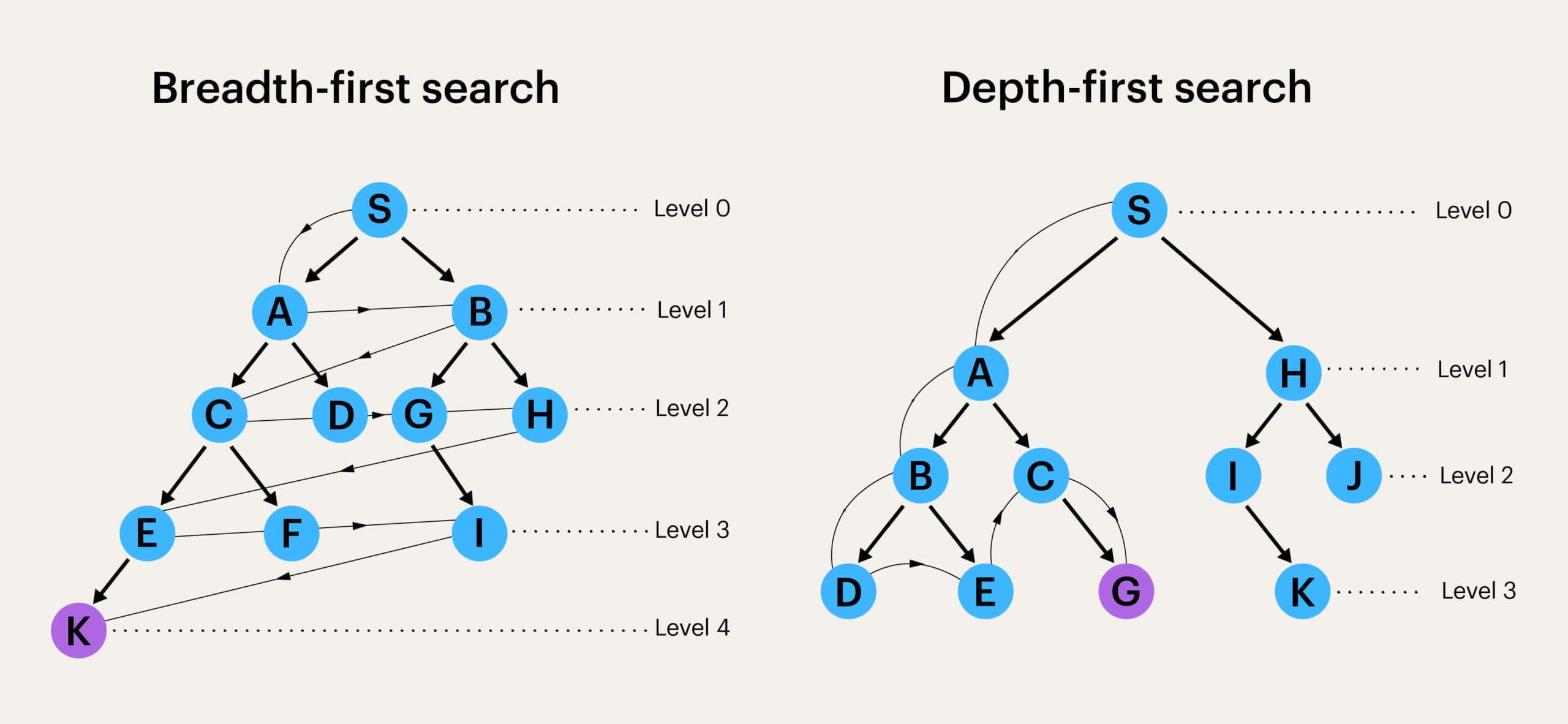
Achieving this balance in practice requires a lot of work.
Case study: Resolution Bot
Resolution Bot is a product that automatically answers the repetitive questions faced by customer support teams. Support teams get a lot of repeated inbound questions, which get tedious to answer. Automating the resolution of those questions helps companies to scale their support – operating online might mean you can sell to anyone in the world, but you better be able to support all those people if you want to retain your brand.
A big risk with a project like this is always end user experience. You might think that for an ML product, the UX is less important than usual – but actually, it’s worth going particularly deep on UX when starting an ML project.
An example of an exceptional end user experience for an ML product is the keyboard suggestions feature on smartphones. Consider how the suggestions subtly appear above the keyboard, without causing friction or irritation if they’re not helpful.
A lot of design effort went into that subtlety, which results in suggestions that are simultaneously noticeable when they’re relevant, but ignorable when they’re irrelevant.
This is what you want to design for – you can ship a first version with machine learning that’s not amazing, but it doesn’t really damage the end user experience, because the design makes the cost of false positives relatively low. Having a low cost of error makes it much easier to get an ML product off the ground – that’s why it’s often best to start with a version that makes suggestions, to mitigate the impact of errors. It might not be intuitive, but extra UX effort here can actually make the machine learning effort much more likely to deliver good results.
“We knew natural language processing is rapidly improving, but was it now good enough to produce the great user experience we needed?”
With this heuristic in mind, we were a little bit nervous when we started work on Resolution Bot. This bot was going to have to unexpectedly interject its way into support conversations. It’s easy to annoy users by interrupting them. What was the cost of a false positive going to be? Machine learning is inherently probabilistic, so there will always be times it interjects with an answer that’s irrelevant. Would end users be glad to see the bot? Would it hurt their experience if the bot was irrelevant? We knew natural language processing is rapidly improving, but was it now good enough to produce the great user experience we needed? That’s a very fine judgment to make, and so very hard to know without prototyping.
Finally, a huge worry for us was the customer set-up experience. Intercom has tens of thousands of customers, and they needed to be able to set up and configure Resolution Bot for each of their businesses without any intervention from us to make this work as a product.
Balancing risks in machine learning development
I believe that for any ML product, you’ve got to find the path that cheaply reduces these different types of risks in a balanced fashion. If you find yourself six months in, and there’s a team working deeply on the machine learning, but haven’t yet shipped versions that customers are using, that’s a really bad sign. You might easily be over-engineering your solution or solving slightly the wrong problem.
Equally, if you spend six months producing a great design, but without reducing technical risk, you can produce a great design which depends on unattainable ML performance, and so never ships. One of our design principles is “what you ship is what matters,” and rightly so.
Instead, you want to carve out and validate an acceptable product envelope as soon as possible, in the breadth-first way described above. Do whatever it takes to define a version of your feature which can deliver value with the simplest machine learning possible. Ship that to customers in some alpha form as quickly as possible, and get the iteration flywheel spinning.
A year in the life of a bot
Resolution Bot took us just under a year to build, from first prototype in November 2017 to launch. I think the ups and downs of that year – the things we are proud of, and the things we messed up – provide a good case study for how to approach an ML project.
During the first six weeks of the project, we built several waves of fast prototypes. Prototype one was just something we hacked together in a week, using Jupyter Notebooks and regular expressions. This enabled us to put something in front of stakeholders internally and check we were broadly aligned as to the project goals. An early working prototype you can interact with provides clarity and definition to ML projects, which often suffer from fuzziness.
“We had seen the magic of a couple of real end users having their questions successfully answered by a bot, and we knew time spent improving accuracy with real machine learning wouldn’t be wasted”
For the next few prototypes, we still didn’t build any machine learning. We took an off-the-shelf Python search engine and built another test bot that could answer our own inbound support queries. We used this off-the-shelf technology for as long as possible, and focused on trying to identify and reduce other types of risk in a balanced fashion.
After six weeks, we had reached prototype four – you could dialogue with it, and our colleagues could give helpful directional feedback. We still hadn’t done any “real machine learning,” but we had seen the magic of a couple of real end users having their questions successfully answered by a bot, and we knew time spent improving accuracy with real machine learning wouldn’t be wasted.
The initial core challenge
Moving fast, and not over-building the technology, allowed us to identify our first real challenge: given a bot that can answer customer questions, how does the bot get content? How does it get the answers to provide to customers? By proceeding in a cupcake fashion, in this breadth-first way, we flushed out this challenge earlier than we otherwise might have.
The solution we reached for was to train the bot by mining historical questions. We prototyped a very quick and dirty JavaScript tool which would put a bank of historical questions through a simple off-the-shelf clustering algorithm. Seeing these clusters helped us figure out what questions we needed to teach the bot how to answer.
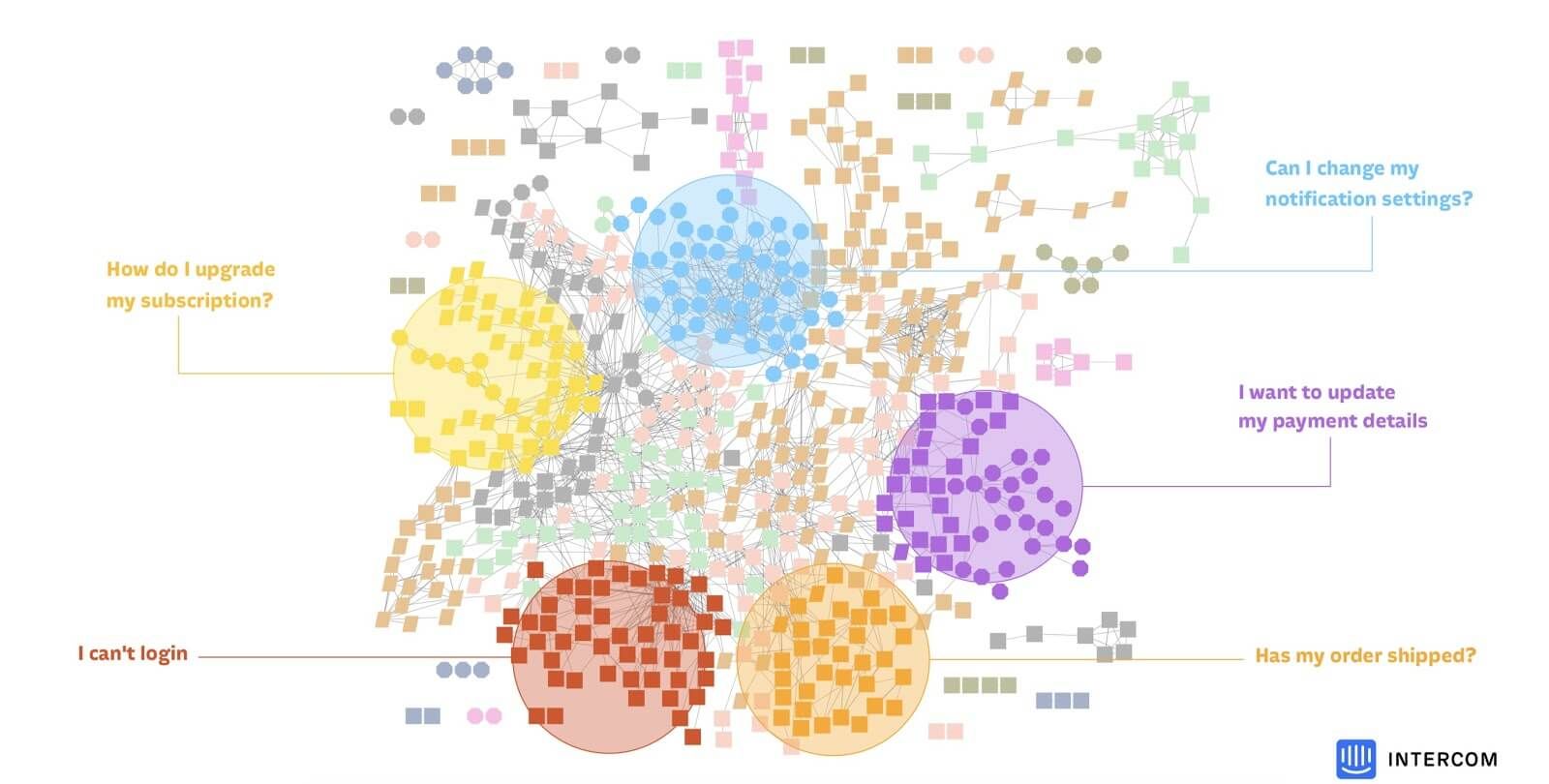
At this point, we had a prototype version of every piece we needed to build a simple bot. No piece was brilliant, but we had identified most risk categories. This enabled us to start a broad internal alpha and we put it live – within two months of starting the project, it was answering real questions for real customers on Intercom.com. We could now iterate from a position of strength, observing live performance as we went. Getting to this point as fast as possible is the best way I know to accelerate a complex machine-learning product.
Executing this whole product loop made us aware of several key constraints:
- First, curating the bot’s replies, so it actually can answer useful questions, takes iteration to get right.
- Second, while our users were very patient with “false positives” – irrelevant suggestions – the Search technology we were using generated a lot of them.
Overall, our biggest learning was that it felt like magic when the bot perfectly answered questions, and the many examples of people instantly getting answers to their questions really motivated us to continue pushing on this product.
Curation poses a design challenge
With these learnings, we were confident enough to move on to full production with the envelope we had carved out, but this was when we really had to confront an incredibly difficult design challenge – the set-up experience for our customers.
Up to this point, we were training the bot ourselves and were sure our users liked it. But could we design a curation interface that our customers could successfully use without understanding how it all worked under the hood?
We hoped we could solve the false-positive issue by having people curate keywords, but several rounds of user research showed this approach didn’t work. We spent many weeks of design iteration trying to make it easy to curate required keywords, but, no matter what we tried, too many customers struggled, frequently ending up with overly restrictive keywords, or sometimes misunderstanding them entirely. At this point, the wheels could have come entirely off the project.
“We started work on a custom machine learning algorithm to replace the off-the-shelf search engine with something more sophisticated”
But we were lucky – this was where our cupcake approach really paid off. By proving the utility of the concept early, we knew that we could afford to invest in solving this problem, and that the effort building a custom solution here wouldn’t be wasted. So we started work on a custom machine learning algorithm to replace the off-the-shelf search engine with something more sophisticated – a custom algorithm would be much more accurate at deciding when it had a good match. We initially used word vectors and a lot of custom code, and now use cutting-edge deep learning.
This worked very successfully. It’s expensive and time consuming to build in-house ML, but this is the best time to spend those resources: when you’ve proven the ML is the bottleneck on a real product problem and know the exact performance thresholds the ML solution has to hit.
We also had another ML challenge on this project. For internal use we successfully used standard topic modelling algorithms to suggest common questions on which to train the bot, but these off-the-self algorithms are difficult to productize.
Often, more theoretical clustering algorithms try to find all possible clusters of data, and to cluster every data point. But when building products, we often want to show customers just the best clusters. So we again ended up writing custom algorithms, designed to be more cautious and selective. We put the output of these algorithms into the product in a very slimmed-down interface, where we just showed the best single example of each cluster. Having a thin interface to the product like this allowed us to iterate rapidly on the underlying ML algorithm, even after launch, without needing to redesign each time. Being very thoughtful about the interface the ML system exposes can really help iteration speed.
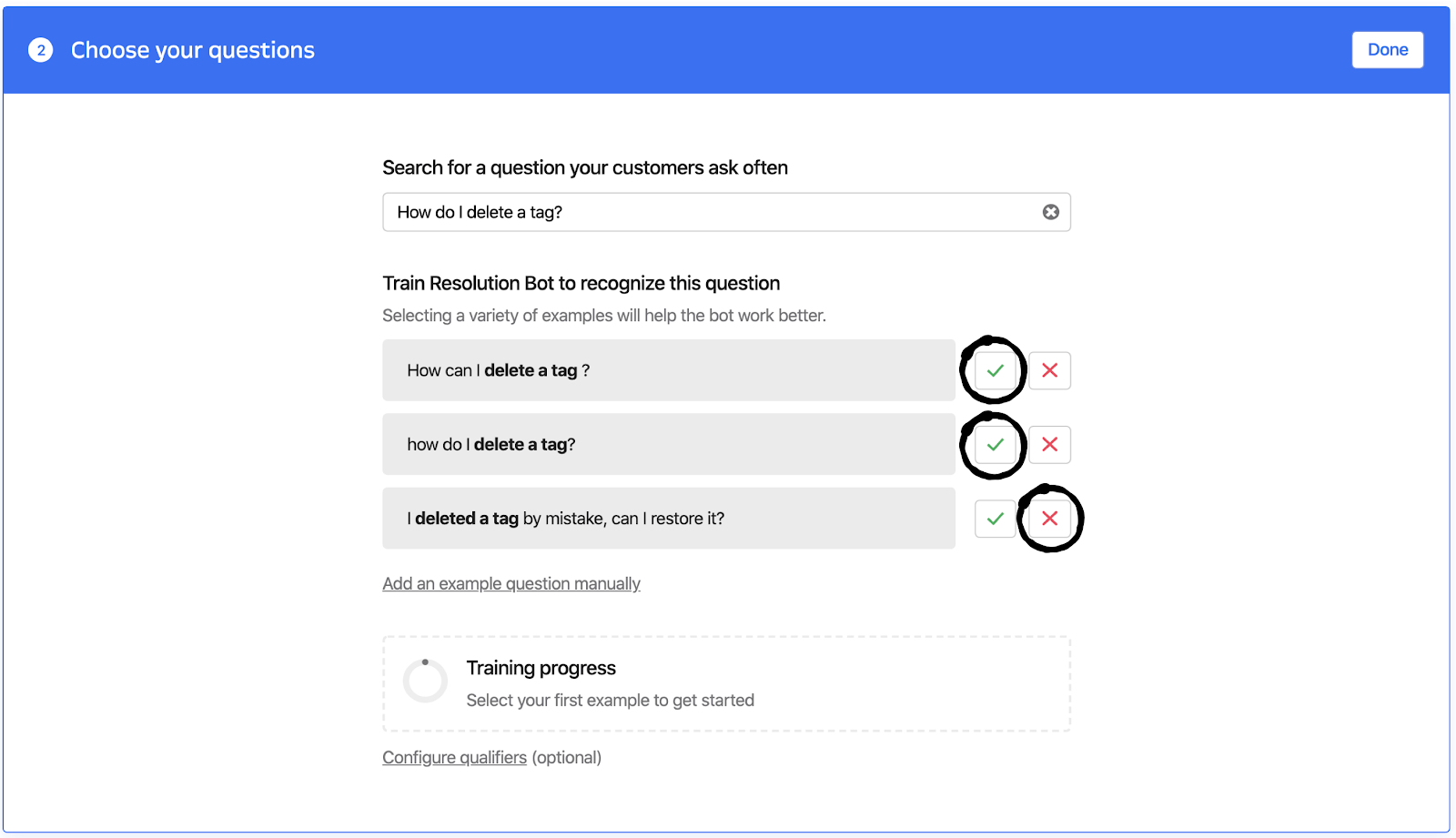

Our metrics showed these suggestions did a great job at reducing initial friction, by helping customers curate their first few answers.
Key takeaways
Resolution Bot launched in October 2018 and went through a significant update (and name change) early this year, and now uses some of the most sophisticated neural network algorithms there are.
But building machine learning products is always risky. You have to balance product and technology risk. My key takeaways from this project are:
- Don’t go and spend six or 12 months and build a beautiful design that just needs an amazing machine learning feature that can’t be delivered, or the other way around.
- Start prototyping as soon as possible with minimal machine learning.
- Test it with as many types of users as you can as soon as possible.
- Resist the temptation to wait until an unrealistically high accuracy threshold has been reached before shipping – shipping early and learning fast is crucial in order to reach that accuracy threshold.
Across the whole industry, we think the ML technology that is now available, is way ahead of application. It’s a very exciting time to be working on machine learning, as there are so many breakthroughs just waiting to be productized and brought to customers.
Resolution Bot is just the start of our vision for this space. We’re incredibly excited about the iterations and innovations that are on the way.
Interested in joining the Intercom engineering team? Take a look at our job openings.







