
Understanding AI: How we taught computers natural language

The phrase “artificial intelligence” has been used in relation to computers since the 1950s, but until this past year, most people probably thought AI was still more sci-fi than tech reality.
The arrival of OpenAI’s ChatGPT in November 2022 suddenly changed people’s perceptions of what machine learning was capable of – but what exactly was it about ChatGPT that made the world sit up and realize artificial intelligence was here in a big way?
In a word, language – the reason ChatGPT felt like such a remarkable leap forward was because of how it appeared fluent in natural language in a way no chatbot has ever been before.
This marks a remarkable new stage of “natural language processing” (NLP), the ability of computers to interpret natural language and output convincing responses. ChatGPT is built on a “large language model” (LLM), which is a type of neural network using deep learning trained on massive datasets that can process and generate content.
“How did a computer program achieve such linguistic fluency?”
But how did we get here? How did a computer program achieve such linguistic fluency? How does it sound so unerringly human?
ChatGPT was not created in a vacuum – it built on myriad different innovations and discoveries over recent decades. The series of breakthroughs that led to ChatGPT were all milestones in computer science, but it’s possible to see them as mimicking the stages by which humans acquire language.
How do we learn language?
To understand how AI has reached this stage, it’s worth considering the nature of language learning itself – we start with single words and then start combining them together into longer sequences until we can communicate complex concepts, ideas and instructions.
For example, some common stages of language acquisition in children are:
- Holophrastic stage: Between 9-18 months, children learn to use single words that describe their basic needs or wants. Communicating with a single word means there is an emphasis on clarity over conceptual completeness. If a child is hungry they won’t say “I want some food” or “I am hungry”, instead they will simply say “food” or “milk”.
- Two-word stage: During the ages of 18-24 months children start to use simple two word grouping to enhance their communication skills. Now they can communicate their feelings and needs with expressions like “more food” or “read book”.
- Telegraphic stage: Between 24-30 months children start to string multiple words together to form more complex phrases and sentences. The number of words used is still small but correct word ordering and more complexity start to appear. Children start to learn basic sentence construction, such as “me wanna show mommy”.
- Multi-word stage: After 30 months children start to transition to the multi-word stage. In this stage children start to use more grammatically correct and complex and multi-clause sentences. This is the final stage of language acquisition and children eventually communicate with complex sentences such as “If it rains I want to stay in and play games.”
One of the first key stages in language acquisition is the ability to start using single words in a very simple way. So the first obstacle AI researchers needed to overcome was how to train models to learn simple word associations.
Model 1 – Learning single words with Word2Vec (paper 1 and paper 2)
One of the early neural network models that attempted to learn word associations in this way was Word2Vec, developed by Tomáš Mikolov and a group of researchers at Google. It was published in two papers in 2013 (which shows how fast things have developed in this field.)
These models were trained by learning to associate words that were commonly used together. This approach built on the intuition of early linguistic pioneers such as John R. Firth, who noted that meaning could be derived from word association: “You shall know a word by the company it keeps.”
The idea is that words which share a similar semantic meaning tend to occur more frequently together. The words “cats” and ”dogs” would generally occur more frequently together than they would with words like “apples” or “computers”. In other words, the word “cat” should be more similar to the word “dog” than “cat” would be to “apple” or “computer”.
The interesting thing about Word2Vec is how it was trained to learn these word associations:
- Guess the target word: The model is given a fixed number of words as input with the target word missing and it had to guess the missing target word. This is known as Continuous Bag Of Words (CBOW).
- Guess the surrounding words: The model is given a single word and then tasked with guessing the surrounding words. This is known as a Skip-Gram and is the opposite approach to CBOW in that we are predicting the surrounding words.
One advantage of these approaches is that you do not need to have any labeled data to train the model – labeling data, for instance describing text as “positive” or “negative” to teach sentiment analysis, is slow and laborious work, after all.
One of the most surprising things about Word2Vec was the complex semantic relationships it captured with a relatively simple training approach. Word2Vec outputs vectors which represent the input word. By performing mathematical operations on these vectors the authors were able to show the word vectors did not just capture syntactically similar elements but also complex semantic relationships.
These relationships are related to how the words are used. The example that the authors noted was the relationship between words like “King” and “Queen” and “Man” and “Woman”.
But while it was a step forward, Word2Vec had limits. It had only one definition per word – for example, we all know that “bank” can mean different things depending on whether you plan on holding one up or fishing from one. Word2Vec didn’t care, it just had one definition of the word “bank” and would use that in all contexts.
Above all, Word2Vec could not process instructions or even sentences. It could only take a word as its input and output a “word embedding”, or vector representation, which it had learned for that word. To build on this single word foundation researchers needed to find a way to string two or more words together in a sequence. We can imagine this as being similar to the two-word stage of language acquisition.
Model 2 – Learning word sequences with RNNs and Sequences of text
Once children have started to master single word usage they attempt to put words together to express more complex thoughts and feelings. Similarly, the next step in the development of NLP was to develop the ability to process sequences of words. The problem with processing sequences of text is that they have no fixed length. A sentence can vary in length from a few words to a long paragraph. Not all of the sequence will be important to the overall meaning and context. But we need to be able to process the entire sequence to know which parts are most relevant.
That’s where Recurrent Neural Networks (RNNs) came along.
Developed in the 1990s, an RNN works by processing its input in a loop where the output from previous steps is carried through the network as it iterates through each step in the sequence.
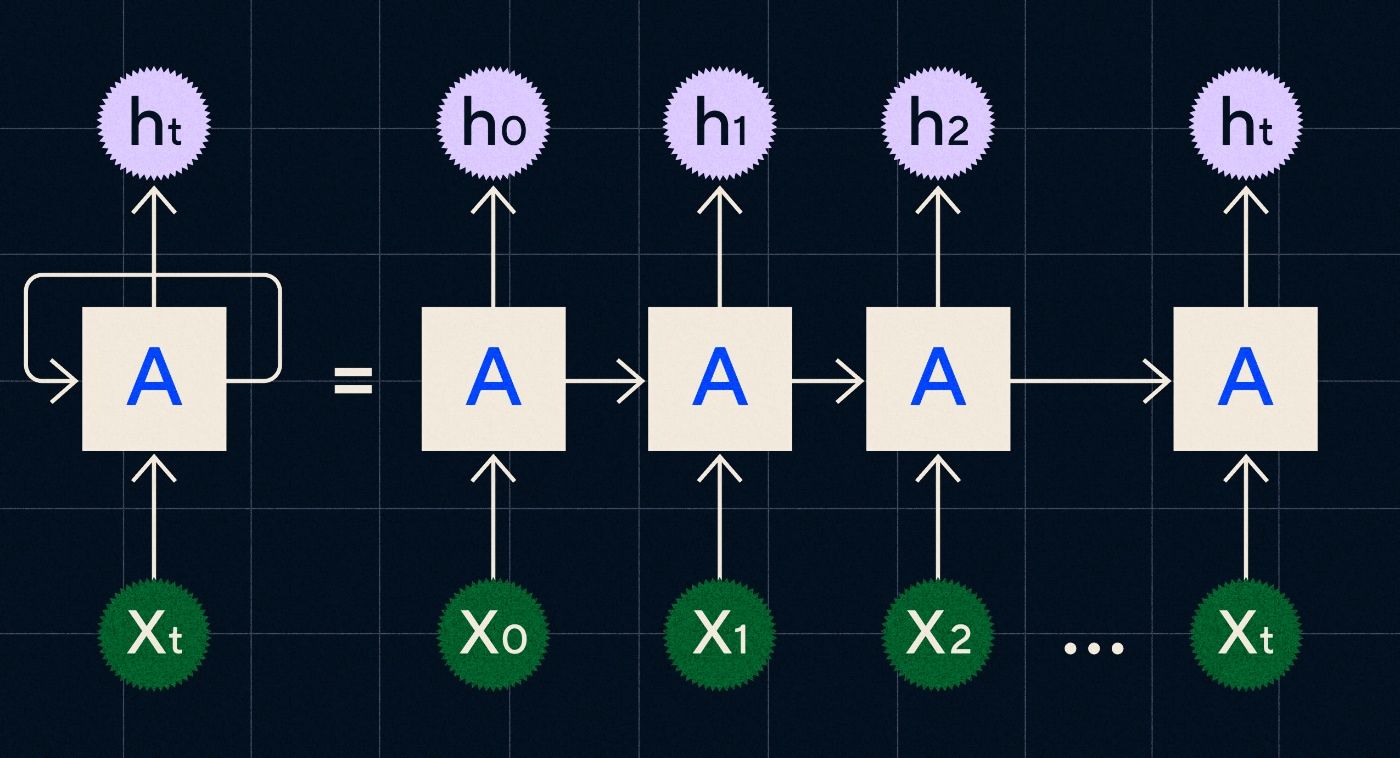
Source: Christopher Olah’s blog post on RNNs
The above diagram shows how to picture an RNN as a series of neural networks (A) where the output of the previous step (h0, h1, h2…ht) is carried through to the next step. In each step a new input (X0, X1, X2 … Xt) is also processed by the network.
RNNs (and specifically Long Short Term Memory networks, or LSTMs, a special type of RNN introduced by Sepp Hochreiter and Jürgen Schmidhuber in 1997) enabled us to create neural network architectures which could perform more complex tasks such as translation.
In 2014, a paper was published by Ilya Sutskever (a co-founder of OpenAI), Oriol Vinyals and Quoc V Le at Google, which described Sequence to Sequence (Seq2Seq) models. This paper showed how you could train a neural network to take an input text and return a translation of that text. You can think of this as an early example of a generative neural network, where you give it a prompt and it returns a response. However, the task was fixed, so if it was trained on translation, you could not “prompt” it to do anything else.
Remember that the previous model, Word2Vec, could only process single words. So if you passed it a sentence like “the dentist pulled my tooth” it would simply generate a vector for each word as if they were unrelated.
However, order and context are important for tasks such as translation. You cannot just translate individual words, you need to parse sequences of words and then output the result. This is where RNNs enabled Seq2Seq models to process words in this way.
The key to Seq2Seq models was the neural network design, which used two RNNs back to back. One was an encoder which turned the input from text into an embedding, and the other was a decoder which took as its input the embeddings outputted by the encoder:
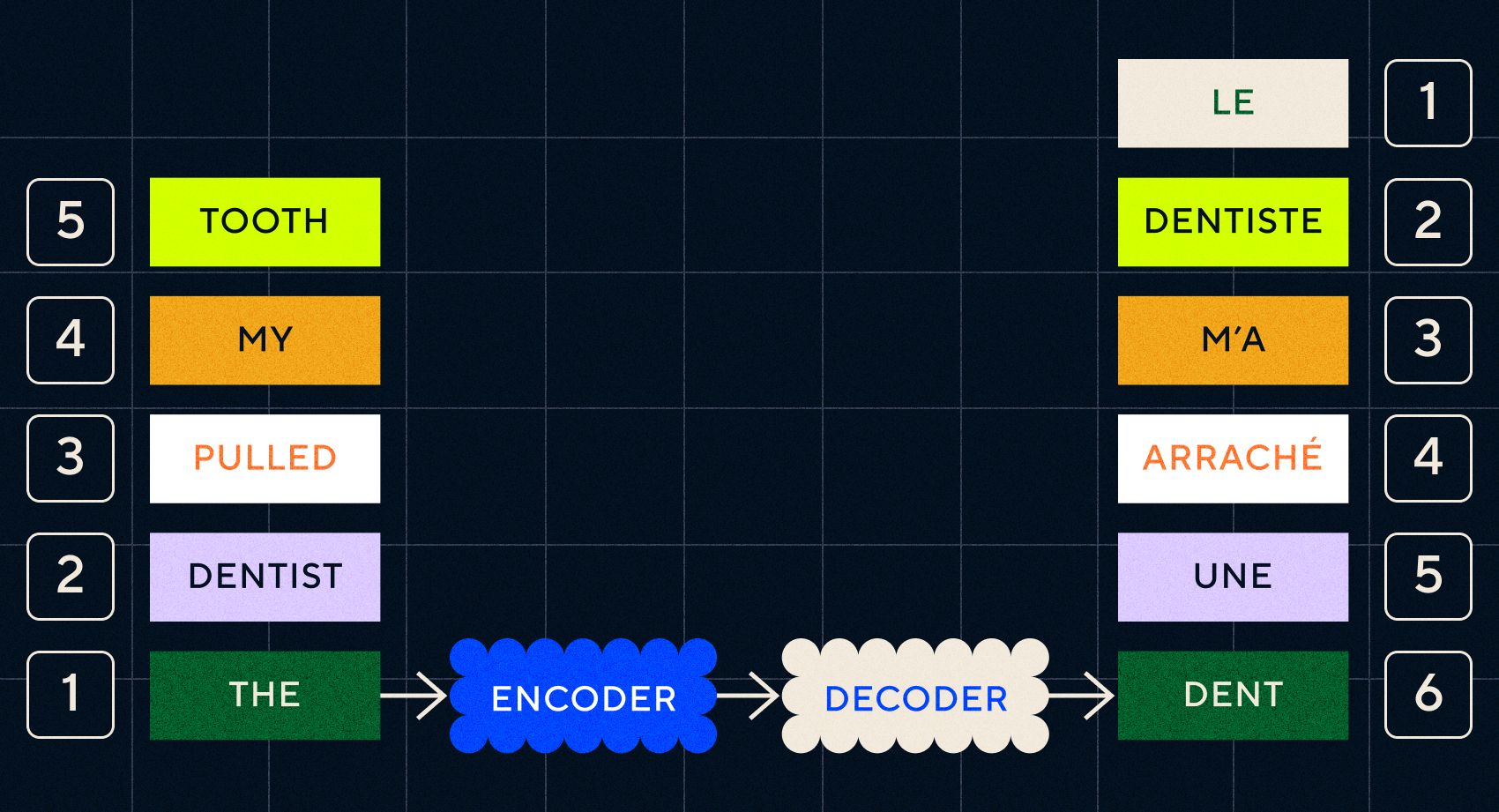
Once the encoder has processed the inputs in each step it then starts passing the output to the decoder which turns the embeddings into a translated text.
We can see with the evolution of these models that they are starting to resemble, in some simple form, what we see today with ChatGPT. However, we can also see how limited these models were in comparison. As with our own language development, to really improve on linguistic abilities we need to know exactly what to pay attention to in order to create more complex phrases and sentences.
Model 3 – Learning by attention and scaling with Transformers
We noted earlier that the telegraphic stages was where children started to create short sentences with two or more words. One key aspect of this stage of language acquisition is that children are beginning to learn how to construct proper sentences.
RNNs and Seq2Seq models helped language models process multiple sequences of words but they were still limited in the lengths of sentences that they could process. As sentence length increases we need to pay attention to most things in the sentence.
For example, take the following sentence “There was so much tension in the room you could cut it with a knife”. There is a lot going on there. To know that we are not literally cutting something with a knife here we need to link “cut” with “tension” earlier in the sentence.
As sentence length increases it becomes more difficult to know which words refer to which in order to infer the proper meaning. This is where RNNs started to encounter limits and we needed a new model to move to the next stage of language acquisition.
“Think of trying to summarize a conversation as it gets longer and longer with a fixed limit of words. At every step you start to lose more and more information”
In 2017, a group of researchers at Google published a paper which proposed a technique to better enable models to pay attention to the important context in a piece of text.
What they developed was a way for language models to more easily look up the context they needed while processing an input sequence of text. They called this approach “transformer architecture”, and it represented the biggest leap forward in natural language processing to date.
This lookup mechanism makes it easier for the model to identify which of the previous words provided more context to the current word being processed. RNNs try to provide context by passing an aggregated state of all the words that have already been processed at each step. Think of trying to summarize a conversation as it gets longer and longer with a fixed limit of words. At every step you start to lose more and more information. Instead, transformers weighted words (or tokens, which are not whole words but parts of words) based on their importance to the current word in terms of its context. This made it easier to process longer and longer sequences of words without the bottleneck seen in RNNs. This new attention mechanism also allowed the text to be processed in parallel instead of sequentially like an RNN.
So imagine a sentence like “The animal didn’t cross the street because it was too tired”. For an RNN it would need to represent all the previous words at each step. As the number of words between “it” and “animal” increase it becomes more difficult for the RNN to identify the proper context.
With the transformer architecture the model now has the ability to look up the word that is most likely to refer to “it”. The diagram below shows how transformer models are able to focus on “the animal” part of the text as they attempt to process a sentence.
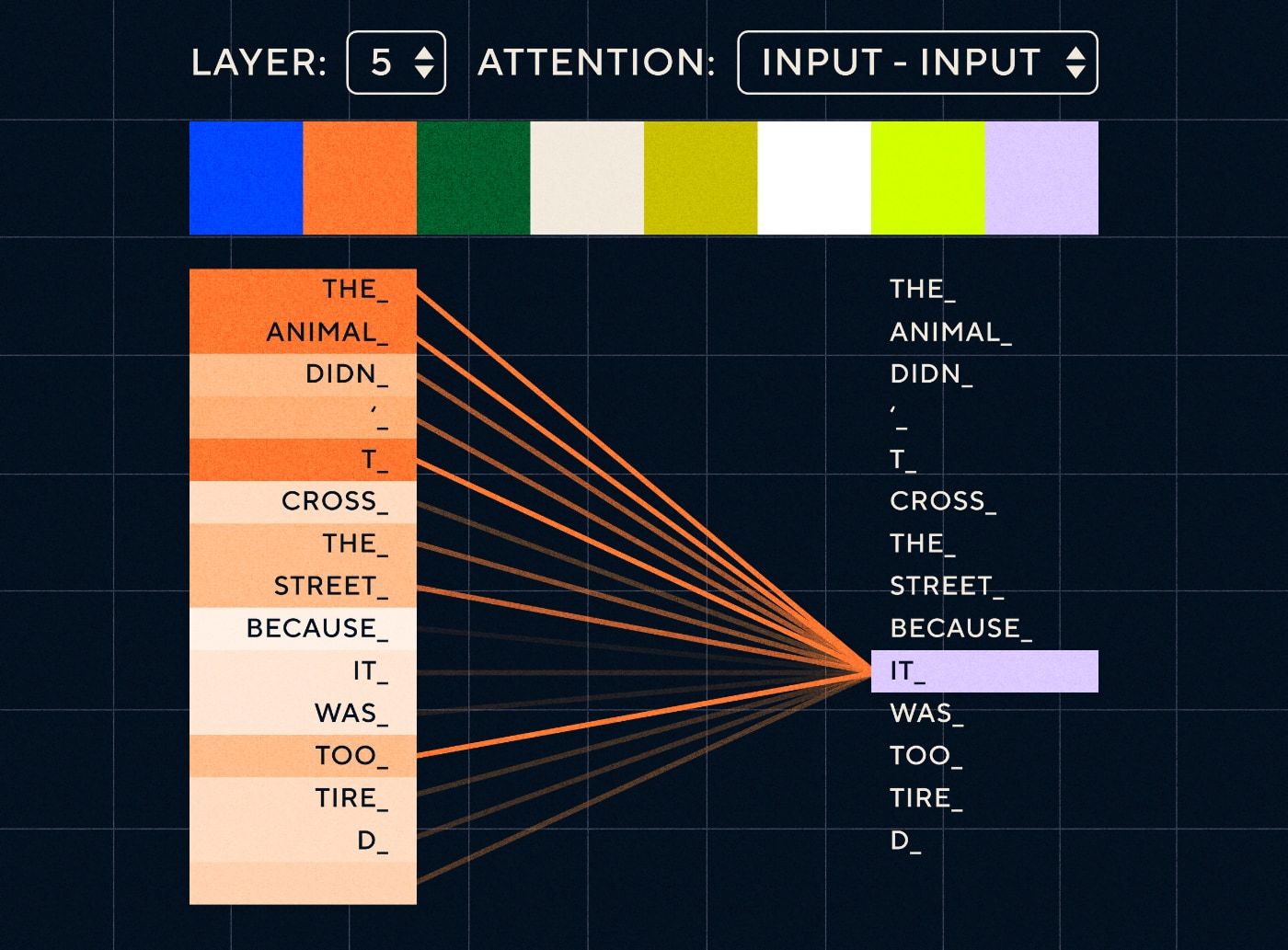
Source: The Illustrated Transformer
The diagram above shows the attention at layer 5 of the network. At each layer the model is building up its understanding of the sentence and “paying attention to” a particular part of the input which it thinks is more relevant to the step it is processing at that time, i.e. it is putting more attention on “the animal” for the “it” in this layer. Source: The illustrated Transformer
Think of it like a database where it can retrieve the word with the highest score which is most likely related to “it”.
With this development, language models were not limited to parsing short textual sequences. Instead you could use longer text sequences as inputs. We know that exposing children to more words via “engaged conversation” helps improve their language development.
Similarly, with the new attention mechanism, language models were able to parse more and varied types of textual training data. This included Wikipedia articles, online forums, Twitter, and any other text data you could parse. As with childhood development, exposure to all these words and their usage in different contexts helped language models develop new and more complicated linguistic capabilities.
It was in this phase that we started to see a scaling race where people threw more and more data at these models to see what they could learn. This data did not need to be labeled by humans – researchers could just scrape the internet and feed it to the model and see what it learned.
“Models like BERT broke every natural language processing record available. In fact, the testing datasets that were used for these tasks were far too simple for these transformer models”
The BERT (Bidirectional Encoder Representations from Transformers) model deserves a special mention for a few reasons. It was one of the first models to utilize the attention feature that is the core of the Transformer architecture. Firstly, BERT was bidirectional in that it could look at text both to the left and right of the current input. This was different from RNNs which could only process text sequentially from left to right. Secondly, BERT also used a new training technique called “masking” which, in a way, forced the model to learn the meaning of different inputs by “hiding” or “masking” random tokens to ensure the model couldn’t “cheat” and focus on a single token in each iteration. And finally, BERT could be fine-tuned to perform different NLP tasks. It did not have to be trained from scratch for these tasks.
The results were amazing. Models like BERT broke every natural language processing record available. In fact, the testing datasets that were used for these tasks were far too simple for these transformer models.
Now we had the ability to train large language models which served as the foundation models for new natural language processing tasks. Previously people mostly trained their models from scratch. But now pre-trained models like BERT and the early GPT models were so good that there was no point in doing it yourself. In fact these models were so good people discovered that they could perform new tasks with relatively few examples – they were described as “few-shot learners”, similar to how most people don’t need too many examples to grasp new concepts.
This was a massive inflection point in the development of these models and their linguistic capabilities. Now we just needed to get better at crafting instructions.
Model 4 – Learning instructions with InstructGPT
One of the things children learn in the final stage of language acquisition, the multi-word stage, is the ability to use function words to connect the information carrying elements in a sentence. Function words tell us about the relationship between different words in a sentence. If we want to create instructions then langage models will need to be able to create sentences with content words and function words that capture complex relationships. For example, the following instruction has the function words highlighted in bold:
- “I want you to write a letter …”
- “Tell me what you think about the above text”
But before we could try and train language models to follow instructions we needed to understand exactly what they knew about instructions already.
OpenAI’s GPT-3 was released in 2020. It was a glimpse of what these models were capable of but we still needed to understand how to unlock the underlying capabilities of these models. How could we interact with these models to get them to perform different tasks?
For example, GPT-3 showed that increasing the model size and training data enabled what the authors called “meta-learning” – this is where the language model develops a broad set of linguistic abilities, many of which were unexpected, and can use those skills to understand a given task.
“Would the model be able to understand the intent in the instruction and execute the task rather than just simply predicting the next word?”
Remember, GPT-3 and earlier language models were not designed to develop these skills – they were mostly trained to just predict the next word in a sequence of text. But, through advances with RNNs, Seq2Seq and attention networks, these models were able to process more text, in longer sequences and better focus on the relevant context.
You can think of GPT-3 as a test to see how far we could take this. How big could we make the models and how much text could we feed it? Then after doing that, instead of just feeding the model some input text for it to complete, we could use the input text as an instruction. Would the model be able to understand the intent in the instruction and execute the task rather than just simply predicting the next word? In a way it was like trying to understand what stage of language acquisition these models had reached.
We now describe this as “prompting”, but in 2020, at the time the paper came out, this was a very new concept.
Hallucinations and alignment
The problem with GPT-3, as we now know, was that it was not great at sticking closely to instructions in the input text. GPT-3 can follow instructions but it loses attention easily, can only understand simple instructions and tends to make stuff up. In other words, the models are not “aligned” with our intentions. So the problem now is not so much about improving the models’ language ability but rather their ability to follow instructions.
It’s worth noting that GPT-3 was never really trained on instructions. It was not told what an instruction was, or how it differed from other text, or how it was supposed to follow instructions. In a way, it was “tricked” into following instructions by getting it to “complete” a prompt like other sequences of text. As a result, OpenAI needed to train a model that was better able to follow instructions like a human. And they did so in a paper that was aptly titled Training language models to follow instructions with human feedback published in early 2022. InstructGPT would prove to be a precursor to ChatGPT later in that same year.
The steps outlined in that paper were also used to train ChatGPT. The instruction training followed 3 main steps:
- Step 1 – Fine-Tune GPT-3: Since GPT-3 seemed to do so well with few-shot learning, the thinking was that it would be better if it was fine-tuned on high quality instruction examples. The goal was to make it easier to align the intent in the instruction with the generated response. To do this OpenAI got human labellers to create responses to some prompts that were submitted by people using GPT-3. By using real instructions the authors hoped to capture a realistic “distribution” of tasks that users were trying to get GPT-3 to perform.These were used to fine-tune GPT-3 to help it improve its prompt-response ability.
- Step 2 – Get humans to rank the new and improved GPT-3: To assess the new instruction fine-tuned GPT-3, the labellers now rated the models performance on different prompts with no predefined response. The ranking was related to important alignment factors such as being helpful, truthful, and not toxic, biased, or harmful. So give the model a task and rate its performance based on these metrics. The output of this ranking exercise was then used to train a separate model to predict which outputs the labellers would likely prefer. This model is known as a reward model (RM).
- Step 3 – Use the RM to train on more examples: Finally, the RM was used to train the new instruction model to better generate responses which are aligned with human preferences.
It is tricky to fully understand what is going on here with Reinforcement Learning From Human Feedback (RLHF), reward models, policy updates, and so on.
One simple way to think of it is that it is just a way to enable humans to generate better examples of how to follow instructions. For example, think of how you would try to teach a child to say thanks:
- Parent: “When someone gives you X, you say thank you”. This is step 1, an example dataset of prompts and appropriate responses
- Parent: “Now, what do you say to Y here?”. This is step 2 where we are asking the child to generate a response and then the parent will rate that. “Yes, that’s good.”
- Finally, in subsequent encounters the parent will reward the child based on good or bad examples of responses in similar scenarios in future. This is step 3, where the reinforcement behavior is taking place.
For its part, OpenAI claims that all it does is simply unlock capabilities that were already present in models like GPT-3, “but were difficult to elicit through prompt engineering alone,” as the paper puts it.
In other words, ChatGPT is not really learning “new” capabilities, but simply learning a better linguistic “interface” to utilize them.
The magic of language
ChatGPT feels like a magical leap forward, but it is actually the result of painstaking technological progress over decades.
By looking at some of the major developments in the field of AI and NLP in the last decade we can see how ChatGPT is “standing on the shoulders of giants”. Earlier models first learned to identify the meaning of words. Then subsequent models put these words together and we could train them to perform tasks like translation. Once they could process sentences we developed techniques that enabled these language models to process more and more text and develop the ability to apply these learnings to new and unforeseen tasks. And then, with ChatGPT we finally developed the ability to better interact with these models by specifying our instructions in a natural language format.
“As language is the vehicle for our thoughts, will teaching computers the full power of language lead to, well, independent artificial intelligence?”
However, the evolution of NLP does reveal a deeper magic that we’re usually blind to – the magic of language itself and how we, as humans, acquire it.
There are still many open questions and controversies about how children learn language in the first place. There are also questions about whether there is a common underlying structure to all languages. Have humans evolved to use language or is it the other way around?
The curious thing is that, as ChatGPT and its descendants improve their linguistic development, these models may help answer some of these important questions.
Finally, as language is the vehicle for our thoughts, will teaching computers the full power of language lead to, well, independent artificial intelligence? As always in life, there is so much left to learn.






